
for the Thai language
| | Internet resource for the Thai language |
F.A.Q. Check out the list of frequently asked questions for a quick answer to your inquiry
recent donations!
Sign-up to join our mailing list. You'll receive email notification when this site is updated. Your privacy is guaranteed; this list is not sold, shared, or used for any other purpose. Click here for more information.
To unsubscribe, click here.
|
November 2003 News Archive This site has been undergoing an unprecedented behind-the-scenes overhaul in the last few weeks. The results have not yet manifested for end users, but these changes will certainly lay a strong foundation for future growth of both our content and technology. First off, the completely rewritten ไทย to English translation feature has now been reenabled after it's inauspicious false start of a few days ago. It is not nearly complete yet, but should provide some functionality for those who are interested. The most widespread change (two days ago) was replacing the skeleton of all the COM objects with a C++ template. This template provides the standard IDispatch functionality which allows the server-side IIS/ASP to access those objects (IDispatch is a convention built on top of COM which allows Visual Basic, VBScript, Java, and other languages to access, and discover interface information about, COM objects). I also changed the core code for my object array template. This C++ template uses the obscure "placement new" and "placement delete" overloads to prevent excessive overhead for arrays of thousands of objects. Many same-size objects are allocated in one large block (eliminating per-allocation overhead), and with the "placement" overloads, they can still be treated as C++ objects. I changed the way this had been done so that the overloads are now template member functions (as opposed to global new/delete overloads), so there is less chance that the overloads will accidentally apply to non-embedded instantiations of the objects. If you still follow that, and are reading this because you're having trouble doing placement with templates (or as class member functions) in MS Visual Studio 6 (or .NET), note this: if you add placement overloads to a class, the compiler requires you to also add non-placement overloads. I'm not entirely sure, but I think this is because both are actually the same function, and the compiler sets a run-time flag on the stack (argument) specifying which to do—placement or non. Also in recent days, several new COM objects have been introduced. One of them, "IDop," represents a component of a phrase, which can be either definition or another phrase. This will have the effect of simplifying and improving the performance of the ASP code, when the requisite changes are made in that layer. Most of the other new COM objects have to do with representing the results of the new, reformulated version of the ไทย-to-English translation feature, which failed so spectacularly in version 1. I am now able to report that UNISCRIBE works great for this. The one major hiccup I had was that my development system is running on XP, which has a better version of this component (usp10.dll) than the Windows 2000 server which runs the site. So when my new stuff was all ready to go and I loaded it to the site, it went "splat." Fortunately, I was able to boot the server in "safe" mode and replace the DLL with the copy from my WinXP system and it seems to work fine. Some build-out remains, but I imagine that the proof-of-concept has been affirmed. The see-saw has been tilted towards the technical, as opposed to the content, side for a while now, but don't worry, it always swings back. It is important to keep the soil fertile so the content can blossom. I am continually surprised at how the content of this project (the Thai language) actually determines the direction of our developments. It's as if it's guiding me, showing me its features which (currently) cannot be manifested, revealing elegance and symmetries in the correct technical decisions that have been made, and penalizing incorrect ones. Uploaded 1037 audio clips recorded by Mak today. Allow me to repost the information here about the problems with the new translation feature: "Sorry, I've had to temporarily disable this new feature becuase it has too many performance problems which are affecting the rest of the site. "Technical details of the problem: "This original version attempts to create a Windows 'Rich Edit' control on the IIS thread in order to use the EM_FINDWORDBREAK message to parse the text. As I suspected, there are many problems with spawning windows from the multithreaded IIS processes (which have no desktop). Mainly, I don't know what kind of message pump is being used, since the COM object which runs this site is an 'in-process' DLL without a message pump, rather than a 'local server' process. "I have just found out that I should be able to rewrite this part of the function using UNISCRIBE. UNISCRIBE is the Windows component that the rich edit uses to do the breaking, so I should be able to bypass creating an edit window (and the related problems altogether). I hated that hack anyway; it was not a good design by Microsoft. "If that doesn't work, I'll have to break the word-breaking function into a separate 'local server' COM object, which manages its message pump properly. "I'm also working on another very cool feature (which I'll keep secret for now) which will make the translator much more useful once it's back up and running." Last night I studied the Win32 UNISCRIBE API in further detail, and I have confidence that this will be a much better solution. I also verified that the USP10 header files and library module are included in the Win32 SDK, and the APIs seem to be well-documented, which is promising. With luck, the translation feature will be back up and running in short order. First release of the new translation feature (experimental - prototype). Found and fixed a bug which affected many of my programming projects, since it was in my binary search module which I use frequently. In some cases, I use the result of a binary search to insert an item into a sorted list. This code was flawed, resulting in an insertion in an incorrect position in certain cases. I don't think the result of locating (or failing to locate) an exact item was affected, so the site search tools were probably ok. I think the only effect manifested on this site was perhaps in the IPNameLookup feature of the left column, which may have consumed inordinate memory. Some of my other projects (such as AudioStation) were more seriously affected. The problem was found, however, thanks to some new work on DBEdit, whereby our trusty editing tool now maintains a complete sorting of all Thai words on-the-fly, which greatly enhances performance when using the program. Previously, the index was rebuilt from scratch each time, using a background sort which was described in this forum a couple weeks ago. This site now has full support for synonyms and antonyms being associated with definitions or phrases. Synonyms are implemented such that each item can participate in exactly one synonym group, which can contain any number of synonymous items. Antonyms are implemented such that each item has its own (private) list of up to 1,024 antonymous items. DBEdit ensures that each of these unidirectional mappings is reciprocated in the opposite direction. If you think about the nature of synonyms and antonyms, you'll see why I implemented them this way. The YPod structure mentioned in a recent posting was created to support this new antonym feature, but it was also retrofitted for use in associating (up to 1024) classifiers with items. This does not change the functionality of classifiers in any way except to enhance performance somewhat and remove a previous limitation on a maximum of 8 classifiers per item. Using the same storage mechanism for classifiers and antonyms simplifies the code, speeds the process of testing and exercising the new code, and allowed the old "XPod" code to be discarded. In order to test the extensive new functions and UI in DBEdit, I entered a large backlog of corrections which had been submitted by site visitors over the past three weeks. The work mentioned in the previous site news articles is progressing, but there is one small unrelated item which I forgot to implement last week: when I switched the "phrase manager" to use an assembly-language version of the binary search (so-called "double indirect binary search"), I forgot that I could also use that new ASM routine for the "category manager." It's not a big deal because we don't have too many categories, but I made the switch anyway. Yesterday, I implemented the new YPod/ypx data structure described in an earlier article. This object implements the storage of multiple short lists of integers, with extremely minimal overhead. To wit, all of the lists are stored in the same, single expandable memory blob, and the caller-held 32-bit "key" which references each list—itself—contains all of the management information required in 10:22 format, namely both the list's size and location (respectively). Much of the new data type support (synonyms, antonyms) is now in place in the database. What remains is to expose a UI for them in DBEdit and then in the web site (via ActiveX). A lot of changes to the custom-programmed internal database that runs this site:
Core database routines for locating an item by its ID number were previously hand-coded in x86 assembly language for maximum performance (see previous blog entry). At the time, this optimization was implemented for "entries" and "definitions" but not "phrases," since this latter used a double-indirection scheme in its data storage model. Today, as an excuse to write some more assembly code, I extended the optimization to include this part of the database as well. I've also been completing some early preparatory phases of the upcoming database format enhancements. One of the most involved has been the modularization of the "dop items list" within a phrase. This is the part of our internal representation of a phrase which consists of a list of sub-words or sub-phrases which make up the larger phrase. This modularization will eventually allow multiple "peer" phrases to refer to the "dop items list" in a single master phrase, which represents an important data normalization that we don't currently implement. This will bind the "peer" phrases to each other more tightly, which will mirror more closely the behavior of entries with multiple definitions. The other planned revisions to the data format this time will be as follows:
Loaded 1074 new audio clips recorded by Prof. Mak today. This includes both single word entries and phrases. The phrases in sections 16-20 of the "Fundamentals" category have all been recorded. Composing yesterday's blog entry caused me to think about the code I had spent all day writing.—the "rather ugly" code. As I was drifting off to sleep, I suddenly realized that I had completely missed the boat; I didn't have to resort to breaking up qsort and the primitive message loop multitasking. I could simply use modern multithreading techniques and exclude the entire window procedure with a critical section. Duh! This method seemed so much cleaner than what I described yesterday, that I ripped out all of Saturday's code and did it over. I now create a thread which blocks on a semaphore (and also an "exit app" event) when there's nothing to do. When the semaphore is released, the thread proceeds with the sort. As it proceeds, it enters a critical section periodically (the critical section which is also claimed by DBEdit's entire message loop). Whenever it leaves the critical section, it checks to see if it should restart the sort. If the sort progresses to completion, an event is set to indicate that the index is usable, and the thread re-blocks. The (now unmodified) qsort function is used for the sort, and the comparison function throws a C++ exception if a restart is required. Very nice. The only other detail was to enable the background sorting when modal dialogs are up. This means exiting the critical section prior to calling DialogBox, and then wrapping each dialog box procedure with Enter/Leave critical section calls, which was accomplished with simple subclassing. This seems to work much more smoothly than the previous solution, which seemed to make the app kind of sluggish. Probably because the PeekMessage was always frantically looping. Now I've switched back to GetMessage, and the use of proper synchronization objects for the sort thread means that nothing is needlessly spinning when the app is truly idle.
An original design decision for our database was that the server's usage would be read-only. This dramatically simplified and optimized the code since there need be no concurrency- or contention-checking code to slow things down. As I have mentioned before, we get our great performance (remember that all our pages are generated on-the-fly) by ensuring that our ActiveX database object is "thread neutral"—this means that IIS is allowed to run as many processing threads in our code simultaneously as it sees fit. Multiple web requests from everyone can overlap, as opposed to stacking up in a single-file queue. If some folks are doing elaborate searches which take a while to process, other web page hits can (and do) come and go without bottlenecking. This concurrency is enhanced by the fact that the server has multiple physical processors. But the simplicity and speed of this design rests on the fact that it's a read-only database when it's running on the server. We do our editing offline with a completely separate software system, a Win32 program called DBEdit (see screenshots at right and in the previous site news entry). The database access portion of DBEdit uses the exact same source code as the server ActiveX object. So, this system also has no provision for handling conflicts which could arise from multiple writers. I have a cool class I call MRSW (multi-reader, single-writer), which could be used to make the database support multiple simultaneous readers and writers. But unless I were to conditionally omit this overhead when building the server modules, there would be a small an unnecessary performance penalty for the web site (unnecessary, that is, unless we wanted to implement the ability for multiple editors around the world to directly edit the dictionary data in-situ, perhaps using a form on a web page). Because of all of this, with our current tools, only one editor can use DBEdit to work on the site data at a time. This has been the case for all of the site's seven year history, but we've had only two or three editors (myself, Bryan, and, until recently, Asda), so the coordination hasn't been too challenging. Perhaps Bryan would agree that the time off that our tag-team methodology enforces is welcome. The reason I mention this, besides the remote possibility of someone's general interest, is that there is another reason why it would be nice if the database did implement proper write concurrency control: the existing DBEdit program could then use multiple threads to improve some aspects of the editing experience. For example, various alphabetically sorted lists could be generated in the background during idle time. This would be very simple using modern multithreaded programming—if the db were provisioned with MRSW. Instead, in order to implement this example feature, I had to use a complex, pseudo-multitasking programming technique that harkens back to the early days of Windows 2.1 (1988 or earlier): message loop idle processing. This was a lot trickier than the modern way. I started by making a private copy of the run-time library's qsort routine. Qsort is an efficient sorting algorithm.
This code allows for the sorting to occur during idle time, but without requiring that the database be instrumented with concurrency awareness. That's because, when the message loop is idle, the program's stack is (mostly) unwound, so there can be no pointers into the database "held open." If you follow this logic closely, you'll also realize that the converse must be carefully obeyed—the qsort routine must refer only to item ID numbers, not pointers, in its processing state. This rather ugly code is further complicated by the need for the "background" sorting task to realize when the database has changed; it needs to abort and start the sort over again—even if it has not yet finished the current pass. This check needs to happen once at the beginning of each chunk of background processing. In other news, I also cleaned out some old dead wood: maintenance of a sorted index which was not really needed any more. I also implemented many new right-click menu features, and applied the tabbed UI concept (mentioned in the previous blog entry) to the Phrase view ("pink screen"). This required a complete re-layout of that screen, which was a hugely tedious chore; but the new pink screen is a vast improvement in elegance and quantity of information shown. Two features (subphrase identification, classifier usage) were converted from main menu/modal dialogs to much more convenient modeless displays on the new tab UI. This inspired a third brand-new feature for DBEdit, an "as prefix" list, on another tab. While these DBEdit features are not directly visible on the website, I believe that by improving the ease and speed with which our editors can work, they will manifest in vastly improved content over the coming years. Next it was on to content. I always like to enter a bunch of content after a lot of programming work, in order to test and put the code through its paces. I caught up with many of the corrections our users have submitted, and then used the relatively new PowerSplit mode ("orange screen") to complete the splitting of the gigantic list of proverbs/idioms that Bryan had submitted a few months back.
This is our "behind-the-scenes" Windows application which we use to manage the dictionary database. It has 4 primary, color-coded screens corresponding to a major area of functionality: yellow for "Entry/Def", rose for "Phrases", green for "Categories", and orange for "PowerSplit." One of these screens is shown at right. In addition, there are many dialogs and menu commands implementing various functions, and several full-screen "merge" modes. This program is written entirely in Win32/C++ (no MFC). Like any aging technology, it periodically needs a major overhaul, and for some reason, today was the chosen day. The main focus today was to clear up the cluttered screens, which had gotten crammed full of options in an ad-hoc way over the years. Yes, that's the new, uncluttered version shown! I moved many controls to a new "tabbed" section (at lower right) which provides a lot more space for new and existing features while still meeting the requirement of running on the 1024x768 screen that Bryan uses. Details of this overhaul are too many to recount, but suffice it to say that our editors' experiences working with our data set should be improved. I completed a batch of updates and corrections which tipped the counter at 25111 entries in our online dictionary. Let me note, for those of you who don't know; although we accept user submissions and corrections, every entry in our dictionary is checked by the editors (me or Bryan) before inclusion. Including the submission source, every entry has at least two, and sometimes three, sources before being approved for our database. This process, although tedious, keeps the quality of our database very high. We have never bulk-loaded data from another source without individual review of each entry. We have also recently been working towards an enhancement in the display of auxiliary verbs. I am attempting to systematize the use of prefixes for auxiliary verbs. This is a long process, but some results can be previewed in definitions 3a-3f on the somewhat extensive page for ได้. Which brings me to a related enhancement which is also brand new—the ability to subdivide the definitions on a page into related groups, and the ability (finally) to specify the order in which definitions appear for a Thai word. The task of reordering existing entries remains, but will be accomplished over time. I should mention that the HTML reference names within a page, which currently take the form #def1, #def2, etc., have not yet changed (as I have not yet decided how to handle legacy links), but legacy links (offsite, message board, blog) which use this format will currently mis-link if the definition order is changed. A new control panel item today lets you display the item ID in the search results table. This is normally only of use to authors who are preparing submissions for the site. Thanks everyone for your support of this site as we have reached the important milestone of 25000 entries in our 6th year! |
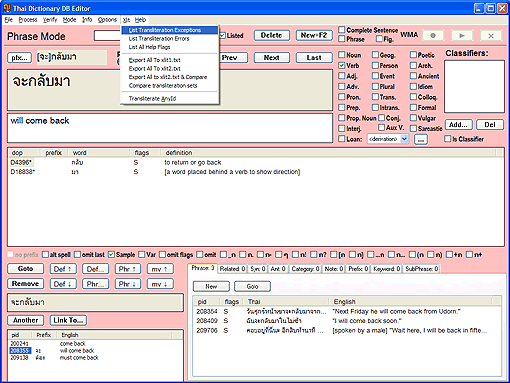 Modifications to our internal tools suite continue at a dramatic pace.
Modifications to our internal tools suite continue at a dramatic pace.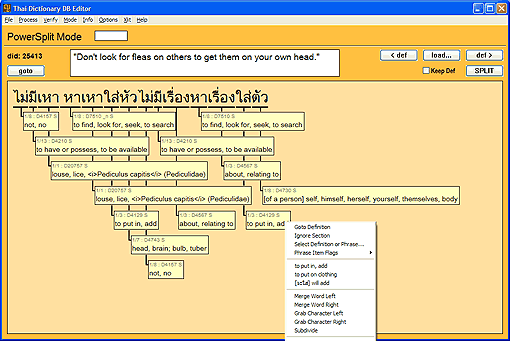 I wrapped all of qsort's local variables into a data structure, encapsulating its processing state, and then broke its code into small chunks so it can run a little bit at a time. In this way, a lengthy qsort is processed incrementally during the idle time of the message loop, which now uses PeekMessage instead of GetMessage.
I wrapped all of qsort's local variables into a data structure, encapsulating its processing state, and then broke its code into small chunks so it can run a little bit at a time. In this way, a lengthy qsort is processed incrementally during the idle time of the message loop, which now uses PeekMessage instead of GetMessage.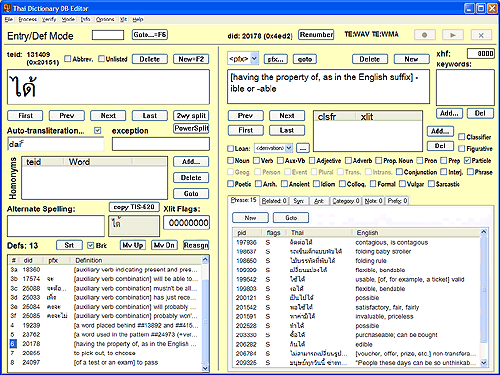 Today I put in 15 nonstop hours implementing a makeover for DBEdit, our primary database management tool.
Today I put in 15 nonstop hours implementing a makeover for DBEdit, our primary database management tool.